Case Study: Emergency Support for Bonnier Publications
Bonnier Publications is the largest publisher of magazines in Northern Europe. They also run a large number of online publications, which makes uptime a critical concern.
As a technology partner, we had assisted Bonnier before in infrastructure optimization. Doing so allowed us to develop a good understanding of Bonnier’s technological setup, which encouraged Bonnier to start involving our emergency incident response squad.
From Yelp to Twitter to Disney, our team has built and maintained several critical services withstanding a tremendous amount of traffic, and as such it has a sharp DevOps skill set and culture.
The team at Life on Mars has helped us a number of times over the past year. Their technical expertise in production systems is impressive and has been crucial. They've done a great job in working with our development team to maximize the uptime of our online properties, as well as restructuring our server infrastructure to optimize our SEO returns. LoM has proved very pragmatic in their approach to the tasks, and very adaptive to our needs. We will continue calling LoM whenever we are in trouble. Head of Projects & Development at Bonnier Publications
Seamless team integration
Bonnier has a sharp and capable development team, who responds quickly and adequately to incidents. However, every minute is precious when you have as strong an online presence as they do. As such, they decided to start involving Life on Mars in order to get at a resolution in the minimum possible amount of time.
Whenever an incident occurs, Bonnier notifies us so that we immediately get our emergency incident response squad online. Our team jumps on a Google Hangouts call with theirs, and is briefed on the observed symptoms and any resolution attempts so far. We’ll then log into their systems, help identify and correct issues, and stay online with their team until the issue is resolved.
Even though adding more people to the mix could make things more hectic, we make sure to not overwhelm the responding team. Since we have a lot of experience operating high traffic services, we’ve developed a keen intuition on why things go wrong at various parts of the system. This helps us to focus on overlooked concerns, complement discovery efforts, and to advise Bonnier on how a larger scale operation would deal with each situation.
Common production issues
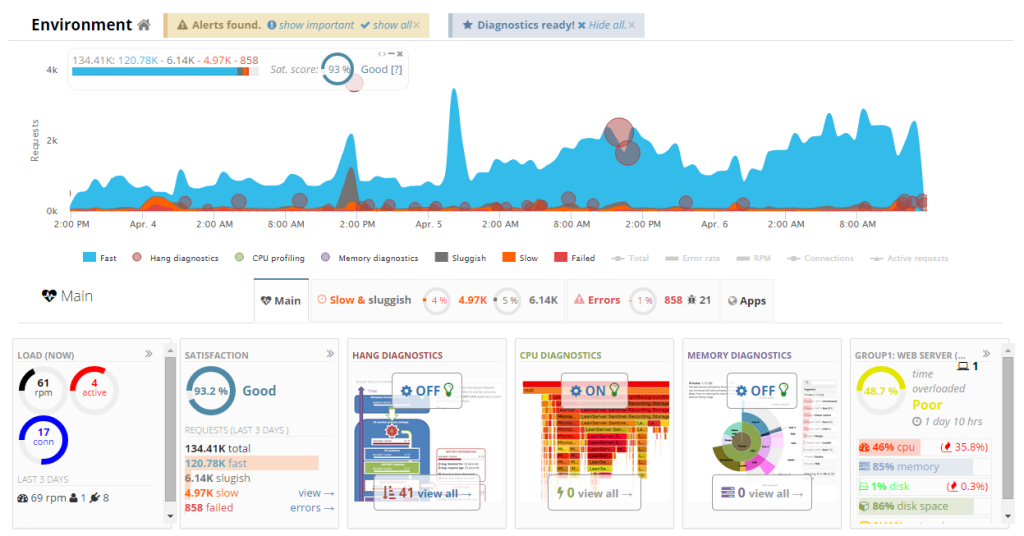
Often, the issues are tied with large, unexpected peaks of traffic. Bonnier’s system boasts a very appropriate amount of slack, but it wouldn’t be economically reasonable to constantly run their systems at 10x capacity to accommodate the occasional peak. Both the application servers and the database may quickly become overloaded, resulting in requests queues clogging up.
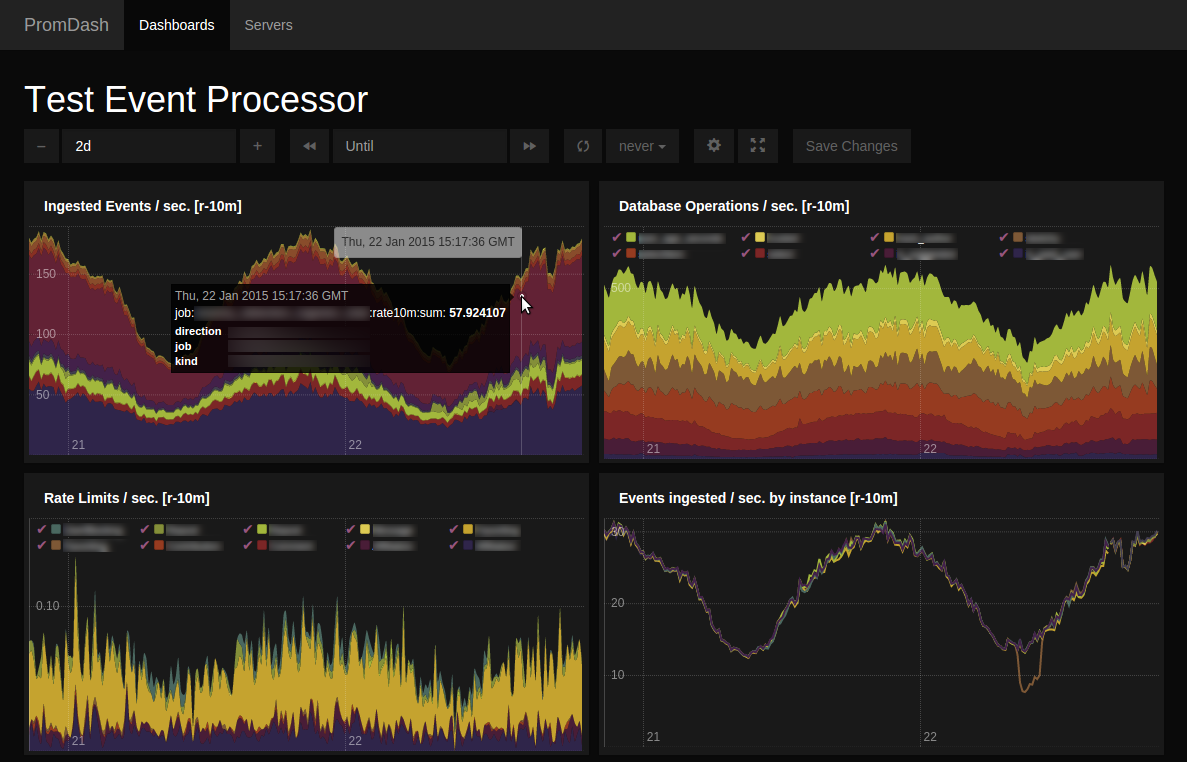
The internet is a big beautiful ball of yarn, held together by duct tape and the brave efforts of the open-source community. Any given system is sitting on a large stack of intricate technologies, which constitute multiple points of failure. As such, heavy instrumentation and constant monitoring are essential for the quick identification of the culprits. Bonnier knows this, and has a solid instrumentation layer which helps us quickly home in on the issue at hand, address it, and see all the red lights turn green.